Spark vs Hadoop: Ktorý je najlepší rámec pre veľké dáta?
Tento príspevok v blogu hovorí o apache spark vs hadoop. Poskytne vám predstavu o tom, aký je správny rámec Big Data pre výber v rôznych scenároch.

Tento príspevok v blogu hovorí o apache spark vs hadoop. Poskytne vám predstavu o tom, aký je správny rámec Big Data pre výber v rôznych scenároch.
Tento blog vám pomôže pochopiť, ako nainštalovať a nastaviť doplnok sbteclipse, s podrobnými pokynmi na spustenie aplikácie Scala v prostredí Eclipse IDE.
Tento príspevok na blogu vysvetľuje, prečo musíte začať používať Apache Spark po Hadoope a prečo učenie Spark po zvládnutí hadoopu dokáže s vašou kariérou zázraky!
Tento výukový program Apache Drill vám poskytne všetky informácie, ktoré potrebujete, aby ste mohli začať s dotazovacím jadrom Apache Drill, používaním s Hadoop, Big Data a Apache Spark.
Tento blog Spark Hadoop vám povie všetko, čo potrebujete vedieť o Apache Spark combineByKey. Nájdite priemerné skóre na študenta pomocou metódy combineByKey.
Apache Falcon je nová platforma na správu údajov pre ekosystém Hadoop, ktorá zjednodušuje integrované spracovanie krmiva a správu krmiva v klastroch hadoop. Naučte sa, ako to nastaviť.
Tento blog Apache Spark podrobne vysvetľuje akumulátory Spark. Naučte sa použitie akumulátora Spark na príkladoch. Akumulátory iskier sú ako počítadlá Hadoop Mapreduce.
V tomto blogu sa dozviete všetko o Apache Flink a nastavení klastra Flink. Flink podporuje real-time a dávkové spracovanie a je nevyhnutnou technológiou Big Data pre Big Data Analytics.
Tento príspevok na blogu pojednáva o distribuovanom ukladaní do pamäte cache s premennými vysielania a uvádza vás do úvahy o efektívnej distribúcii veľkých hodnôt v programovaní Spark.
Certifikácie CCA a CCP od spoločnosti Cloudera nahradili skúšky CCDH a CCSHB. Tento blog vám poskytne všetko, čo potrebujete vedieť o nových certifikáciách.
Tento blogový príspevok pojednáva o stavových transformáciách s vytváraním okien v Spark Streamingu. Dozviete sa všetko o sledovaní údajov v dávkach pomocou stavových streamov D-stream.
Tento blogový príspevok pojednáva o stavových transformáciách v Spark Streamingu. Dozviete sa všetko o kumulatívnom sledovaní a zručnostiach pre kariéru Hadoop Spark.
Technológie Hadoop a Big Data znamenajú revolúciu v analytike v zdravotníctve. Tento blog o veľkých dátach v zdravotníctve pojednáva o tom, ako môže analýza veľkých dát vylepšiť lekársku starostlivosť.
Tento blogový príspevok o streamovaní Hadoop je podrobným sprievodcom, ktorý sa naučí písať program Hadoop MapReduce v Pythone na spracovanie obrovského množstva veľkých dát.
Tento blog o výučbe veľkých dát vám poskytne kompletný prehľad o veľkých dátach, ich vlastnostiach, aplikáciách a výzvach s veľkými dátami.
Tento blog Výukový program HDFS vám pomôže porozumieť systému HDFS alebo distribuovanému súborovému systému Hadoop a jeho funkciám. Stručne tiež preskúmate jeho základné komponenty.
V tomto výučbe Splunk pochopte rozdiely medzi Splunk vs. ELK vs. Sumo Logic a určite, ktorý z týchto nástrojov vám najlepšie vyhovuje.
V tomto blogu o použití aplikácie Splunk pochopíte, ako spoločnosť Domino's Pizza použila spoločnosť Splunk na získanie poznatkov o správaní spotrebiteľov a formulovanie ich obchodných stratégií.
Tento tutoriál je podrobným sprievodcom inštaláciou klastra Hadoop a jeho konfiguráciou na jednom uzle. Všetky kroky inštalácie Hadoop sú pre stroj CentOS.
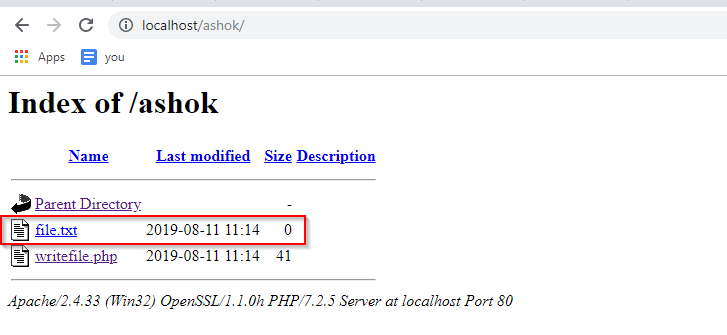
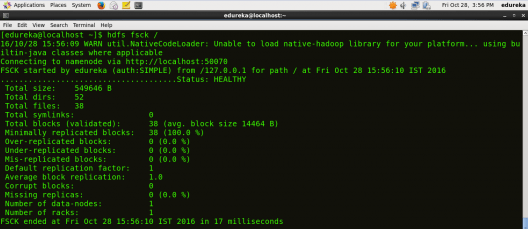
Tento blog hovorí o rôznych príkazoch HDFS, ako sú fsck, copyFromLocal, expunge, cat atď., Ktoré sa používajú na správu súborového systému Hadoop.